个人笔记记录
Java预科
冯诺依曼体系结构

基本的DOS命令
打开CMD的方式
-
开始+系统+命令提示符
-
Win键+R输入cmd打开控制台(推荐使用)
-
在任意的文件来下面,按住 shift键+鼠标右键点击,在此处打开命令行窗口
-
资源管理器的地址输入:cmd + 空格 + 绝对路径(在运行代码文件的时候有用)
以管理员身份运行CMD
按Ctrl+Q进入开始菜单的搜索栏,输入cmd,点击以管理员身份运行
常用的DOS命令
# 盘符切换
D:
C:
E:
# 查看当前目录下的所有文件 (directory)
dir
# 切换目录 (change directory)
cd /d 完整路径
# 进入当前的上一级目录
cd ..
# 进入当前的下一级目录
cd 文件夹
# 清理屏幕 (clear screen)
cls
# 退出终端
exit
# 查看电脑ip配质 (ip configure)
ipconfig
#打开应用
# 计算器 (calculator)
calc
# 画图工具 (Microsoft painter)
mspaint
# 记事本
notepad
# 网络命令
# ping命令 (测试网络是否互通,粗略判断传输质量)
ping www.baidu.com
# netstat命令 (查看各端口网络连接情况)
netstat -ano
# -a : 显示所有活动的 tcp 连接,以及计算机监听的 tcp 和 udp 端口
# -n : 只以数字形式显示所有活动的 tcp 连接的地址和端口号
# -o : 显示活动的 tcp 连接并包括每个连接的进程id (PID)
# 查找使用给定端口的活动连接和PID
netstat -aon|findstr "1080"
# 显示所有正在运行的进程
tasklist
# 查找给定PID对应的运行中的进程
tasklist|findstr "4568"
# 终止指定的进程
taskkill /f /im 进程名称
taskkill /f /pid 进程PID
# /f : 强制终止,有时会缺少权限无法强制终止,需要管理员权限运行
# 文件操作
# 新建目录 (make directory)
md 目录名
# 移除目录 (remove directory)
rd 目录名
# 新建文件
cd> 文件名
# 删除文件
del 文件名
注意DOS不区分大小写
注意路径分隔符是\,而参数命令的标识符是/
如何路径中含有空格,需要用双引号""将整个路径括起来
在DOS中不要用ctrl+c来复制ctrl+v来粘贴,因为ctrl+c会退出当前命令,用鼠标左键框选内容后,鼠标单击右键即可复制,再用鼠标单击右键即可粘贴
计算机语言
第一代语言
机器语言
- 基本计算方式是基于二进制的方式
- 这种代码是直接给计算机使用的,不经过任何转换
第二代语言
汇编语言
- 解决人类无法读懂机器语言的问题
- 指令替代二进制
- 应用:机器人,病毒,逆向工程 (对目标产品进行逆向分析,得出该产品的各项设计流程和要素,从而做出相近但不完全一样的产品)
第三代语言
- 摩尔定律 (集成电路上可以容纳的晶体管数目在大约每经过18个月便会增加一倍。换言之,处理器的性能每隔两年翻一倍。)
高级语言
大体上分为面向过程和面向对象的语言
例如C语言是典型的面向过程的语言,C++、JAVA是典型的面向对象的语言
发展历程:C语言 - C++ - JAVA - C# - Python, PHP, JavaScript
Java入门
Java三大版本与JDK JRE JVM
JavaSE = java standard edition
JavaME = java micro edition
JavaEE = java enterprise edition
其中JavaME基本已经无人使用
JDK = Java Development Kit
JRE = Java Runtime Environment
JVM =Java Virtual Machine
三者是包含与被包含关系

安装开发环境
在oracle官网搜索JDK8,注册账户同意协议并下载安装
(因为企业基本用的都是JDK8,不要下载最新的JDK13或者15)
注意选中取消公共JRE的安装
(因为JDK已经有一个专用JRE了)
配置环境变量:
系统变量:名称—JAVA_HOME,值—安装目录
系统变量下的Path:增加 %JAVA_HOME%\bin 和 %JAVA_HOME\jre\bin
测试 JDK:打开cmd输入java -version
另外,建议下载Notepad++作为文本编辑器
Notepad++默认是单实例运行的(会打开上次未关闭的所有文件),如果想更改成记事本那样的多实例需要在设置里面更改
此外,设置.java文件的默认打开方式为notepad++,方法:win10设置文件默认打开方式为notepad++,其中不设置兼容性也可,只要右键以管理员身份打开即可
安装目录介绍:
bin文件夹(binary):存放二进制可执行程序exe
include:存放c和c++的头文件,因为jdk是用c和c++编写的
jre:Java运行环境
lib(library):存放Java的类库文件
src.zip:存放Java类
HelloWorld
新建一个Code文件夹用于存放代码
在文件夹下新建一个Hello.txt文件后缀名改为.java
用notepad++打开输入以下代码:
public class Hello{
public static void main(String[] args){
System.out.print("Hello, world!");
}
}
在Code文件夹下打开cmd
输入javac Hello.java
输入java Hello
即可运行成功
含义:
javac:是编译命令,将java源文件编译成同名的class字节码文件
例如:javac Hello.java将在java文件的同目录下生成Hello.class文件
java:是运行class字节码文件,由java虚拟机对字节码进行解释和运行
例如:java Hello将成功解释运行Hello.class文件,打印Hello, world!
注意点:
- 注意java命令后面的文件名不用加.class后缀,已经默认是.class后缀了
- java是大小写敏感的,所以javac和java命令内容一定要分清大小写
- 代码内容尽量使用英文,有些缺少GBK支持可能报错
- 注意类名必须和文件名一样,并且首字母大写
编译型和解释型
计算机运行代码需要将源代码转换成机器码,也就是二进制指令,根据转换的时机不同,编程语言可分为编译型和解释型
- 编译型:必须提前将所有源代码一次性转换成二进制指令,也就是生成一个可执行程序,比如C语言、C++等
- 解释型:可以一边执行一边转换,需要哪些源代码就转换哪些源代码,不会生成可执行程序,比如 Python、JavaScript、PHP、Shell、MATLAB等
- Java和 C#是一种比较奇葩的存在,它们是半编译半解释型的语言,源代码需要先转换成一种中间文件(字节码文件),然后再将中间文件拿到虚拟机中执行
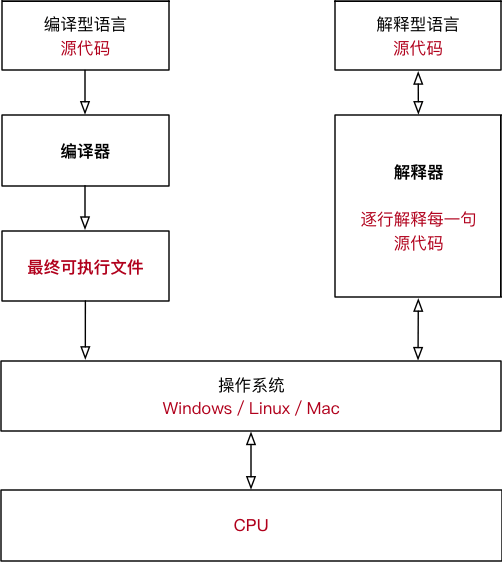
优缺点:
编译型:
对于编译型语言,开发完成以后需要将所有的源代码都转换成可执行程序,比如 Windows 下的.exe文件,可执行程序里面包含的就是机器码。只要我们拥有可执行程序,就可以随时运行,不用再重新编译了,也就是“一次编译,无限次运行”。
在运行的时候,我们只需要编译生成的可执行程序,不再需要源代码和编译器了,所以说编译型语言可以脱离开发环境运行。
编译型语言一般是不能跨平台的,也就是不能在不同的操作系统之间随意切换。
编译型语言不能跨平台表现在两个方面:
1) 可执行程序不能跨平台:因为不同操作系统对可执行文件的内部结构有着截然不同的要求(windows是.exe,linux是.elf)
2) 源代码不能跨平台:不同平台支持的函数、类型、变量等都可能不同
解释型:
对于解释型语言,每次执行程序都需要一边转换一边执行,用到哪些源代码就将哪些源代码转换成机器码,用不到的不进行任何处理。每次执行程序时可能使用不同的功能,这个时候需要转换的源代码也不一样。
因为每次执行程序都需要重新转换源代码,所以解释型语言的执行效率天生就低于编译型语言,甚至存在数量级的差距。计算机的一些底层功能,或者关键算法,一般都使用 C/C++ 实现,只有在应用层面(比如网站开发、批处理、小工具等)才会使用解释型语言。
在运行解释型语言的时候,我们始终都需要源代码和解释器,所以说它无法脱离开发环境。
当我们说“下载一个程序(软件)”时,不同类型的语言有不同的含义:
1) 对于编译型语言,我们下载到的是可执行文件,源代码被作者保留,所以编译型语言的程序一般是闭源的。
2) 对于解释型语言,我们下载到的是所有的源代码,因为作者不给源代码就没法运行,所以解释型语言的程序一般是开源的。
相比于编译型语言,解释型语言几乎都能跨平台,“一次编写,到处运行”是真是存在的,而且比比皆是。解释型语言能跨平台要归功于解释器。
我们所说的跨平台,是指源代码跨平台,而不是解释器跨平台。解释器用来将源代码转换成机器码,它就是一个可执行程序,是绝对不能跨平台的。
官方需要针对不同的平台开发不同的解释器,这些解释器必须要能够遵守同样的语法,识别同样的函数,完成同样的功能,只有这样,同样的代码在不同平台的执行结果才是相同的。
你看,解释型语言之所以能够跨平台,是因为有了解释器这个中间层。在不同的平台下,解释器会将相同的源代码转换成不同的机器码,解释器帮助我们屏蔽了不同平台之间的差异。
Java程序运行机制

这里的类装载器就是JVM,字节码校验器检查语法错误
使用IDEA开发
IDE:集成开发环境,Integrated Development Environment,是用于提供程序开发环境的应用程序,例如eclispe、idea、visual studio
IDEA一般被认为是最好的Java开发工具之一,公司是JetBrains,和PyCharm同一个公司
百度搜索idea进入JetBrains官网,选择IntelliJ IDEA下载Ultimate版本(收费但是可以破解,参考三种方法),不要下载community版本,因为后面的课程会用到JavaScript和SQL,而community版本虽然免费但是是没有这些功能的
安装时只勾选三项64-bit launcher, Add "Open Folder as Project", .java,另外不要放在C盘因为会越用越大
新建Project时选中Java,SDK选择安装的JDK版本(一般会自动锁定)
新建Hello的project
在项目文件夹的src子文件夹下(类文件夹)新建Java Class(.java文件)
输入psvm(缩写)或者main都可以自动补足为public static void main(String[] args){}
输入sout可以补足为System.out.println();
(println和print的唯一区别就是最后会换行,等同于print("xxx\n"),printf和C中的printf一样格式化输出)
与PyCharm不同,在代码行数的绿色▶按钮即可运行.java文件
设置优化IDEA,参考IDEA的常见的设置和优化(功能)和IntelliJ IDEA 性能优化
其中优化类注释和方法注释:最好参考IDEA类和方法注释模板设置(非常详细),其中Param的default value改为
groovyScript("def result=''; def params=\"${_1}\".replaceAll('[\\\\[|\\\\]|\\\\s]', '').split(',').toList(); for(i = 0; i < params.size(); i++) {if(i==0){result+= params[i] + ((i < params.size() - 1) ? '\\n' : '')}else{result+=' * @param ' + params[i] + ((i < params.size() - 1) ? '\\n' : '')}}; return result", methodParameters())
return的值可以改成在expression处选中methodReturnType()
另外不建议方法注释的快捷键是Enter,最好用Tab,因为Enter会让多行注释不方便换行
快捷键
- Ctrl + [ 和 Ctrl + ] 分别是匹配当前指针位置的上一级左大括号和右大括号,在代码特别长的时候很有用
- CTRL + SHIFT + ENTER 在当前行任何地方可以快速在末尾生成分号,并且将代码规范化(添加空格)
- CTRL + D 是复制当前行并粘贴到下一行(Duplicate)CTRL + Y 是删除当前行,在IDEA里面的Redo被换成了Ctrl + Shift + Z
- ALT + ENTER 是引入(补全)局部变量,例如在
Math.pow(2, 3);前后或者中间按下快捷键,就会变成double pow = Math.pow(2, 3); - 按住CTRL鼠标左键点击工具类,可以进入类的源码,点击包,可以在左侧进入包的源路径
Java基础
注释
新建项目流程:
- 一般新建项目不要选择Java而是选择Empty空项目
- 而后从菜单新建module模块,选中Java和对应的SDK
- 最后从工具栏或者菜单栏打开Project Structure - Project,选择SDK和对应的Language Level(也就是8)
- 最后在module的src里面新建Java Class开始编写
要养成书写注释(Comments)的好习惯,不然不仅是别人看不懂,自己过几天也会看不懂,增加时间成本
单行注释(Line Comments)://开头,快捷键Ctrl + /
多行注释(Block Comments):/*开头,*/接尾,快捷键Ctrl + Shift + /
文档注释(JavaDoc):/**开头再按Enter,快捷键/* + Tab(只有按照上一节使用IDEA开发设置了优化方法注释才可以)
注意区分注释(Comments)和注解(Annotations),注解是会被读取运行的,注释不会
标识符和关键字
标识符
1、定义
在Java程序中,所有的由程序员自己命名的元素统称为“标识符”
2、标识符命名规则
标识符由数字、字母、_和$组成
标识符不能以数字开头
标识符区分大小写
标识符不能是关键字
注意:
定义类名的标识符,首字母必须大写,后面的单词首字母大写,遵循“大驼峰命名法”
(例如XxxXxxx)
定义方法标识符:首字母尽量小写,后面的单词首字母大写,遵循“小驼峰命名法”
(例如 xxxXxx)
定义变量的标识符:同小驼峰
定义包名:按模块分层级,使用公司的域名倒写,(例如 com.j2008.xxx)
定义项目名:尽量使用英文(Java项目可以使用中文,JavaWeb项目一定使用英文)
所有标识符尽量使用英文,不建议用拼音和中文
关键字
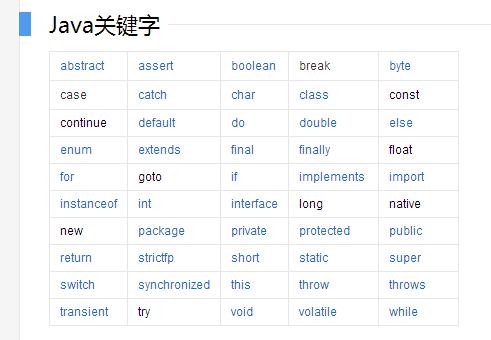
1、定义
Java关键字是电脑语言里事先定义的,有特别意义的标识符,有时又叫保留字,还有特别意义的变量。Java的关键字对Java的编译器有特殊的意义,他们用来表示一种数据类型,或者表示程序的结构等,关键字不能用作变量名、方法名、类名、包名和参数,一共有50个关键字(48关键字+2保留字),关键字都是小写的英文单词。
2、Java的50个关键字
数据类型
强类型语言:一种强制类型定义的语言,一旦某一个变量被定义类型,如果不经过强制转换,则它永远就是该数据类型了,强类型语言包括Java、.net 、Python、C++等语言
例子:定义了一个整数,如果不进行强制的类型转换,则不可以将该整数转化为字符串
弱类型语言:一种弱类型定义的语言,某一个变量被定义类型,该变量可以根据环境变化自动进行转换,不需要经过显性强制转换。弱类型语言包括vb 、PHP、JavaScript等语言
例子:
var A =5;
var B = "5";
SumResult = A +B;
MinResult = A -B;
输入SumResult的答案不是10,而是55,再次是将A的类型转化为了字符串,然后进行拼接。输入MinResult的答案是0,是将B的类型转化为了数字,然后进行减法。
Java的数据类型分为基本类型和引用类型两大类
基本类型
(primitive type)
(笔试常考)

补充:其中boolean类型占1位
其中整数类型常用int(也是默认),浮点数类型常用double(也是默认)
范围:long>int>short>byte,double>float
注意定义long和float变量的时候,需要在赋值的数字后面分别加上L和F,也可以在赋值的数字前面分别加上(long)和(float)做强制转换但是不推荐(因为不是所有东西都可以强制转换)
因为赋值的数字默认是int(整数)和double(小数),而赋值的时候被赋值的变量和赋值的变量(包括数字和字符串)需要是同一数据类型,例如不能将数字赋值给String变量,而Java只会自动将范围小的数据类型转为范围大的(对于int常数来说称为**Java的常量优化机制**),反过来转换需要强制转换(因为有舍入误差)
如果不加L,当long变量赋值的数字在int范围内时,虽然可以将数字自动转换为long类型,再赋值给long变量;但是当数字超出int范围时,Java会认为这个数字不符合int类型,这个数字的数据类型不明确(数字本身就是一种定义,默认为int),无法进行变量定义,此时则需要在数字后面加上L,强制转换成一个long类型的数字,才能再赋值
如果不加F,当float变量赋值的数字是整数在int范围内时,虽然由于float取值范围大于int,可以把数字自动转换成float再赋值;但是如果float变量赋值的数字是浮点数时,浮点数默认是double类型,而float的范围又小于double,由于只会自动将范围小的数据类型转为范围大的,所以浮点数不会自动转换成float,无法与被赋值的float变量匹配,因此无法正常定义;此外,如果float变量赋值的数字是整数但是超出int范围时,同样Java会认为这个数字不符合int类型,这个数字的数据类型不明确,无法进行变量定义,此时则需要在数字后面加上F,强制转换成一个float类型的数字,才能再赋值
注意:Java的常量优化机制只有当等号右边仅含常量时才会生效,右边含有变量是不生效的
例子:
public class Demo1 {
public static void main(String[] args) {
float a = 3.14F;
long b = 1000000000000L;
byte c = 10 + 30;
System.out.println(getType(a));
System.out.println(getType(b));
System.out.println(getType(c));
}
private static String getType(Object a) {
return a.getClass().toString();
}
}
//以下为错误示范,这种情况下常量优化机制是不生效的
public class Demo1 {
public static void main(String[] args) {
int a = 10;
byte b = a + 30;
}
}
另外注意1e3和1000是不一样的,1e3 = 1.0*Math.pow(10,3),默认是double类型,1000默认是int类型
char是字符,String才是字符串,char只能定义一个字(不能空可以空格)且必须单引号不能双引号,String不是关键字是一个类(可以空),且只能双引号不能单引号
boolean是布尔值,只能赋值true或false
public class Demo1 {
public static void main(String[] args) {
char firstname = '陈';
String lastname = "灿东";
boolean male = true;
boolean female = false;
}
}
引用类型
(reference type)

这里先知道有哪些引用类型即可,后续会慢慢讲到
字节
位(bit):是计算机内部数据儲存的最小単位,11001100是ー个8位二进制数
字节(byte):是计算机中数据处理的基本单位,习惯上用大写B来表示
1 B(byte字节)= 8 bit(位)
字符:是指计算机中使用的字母、数字、字和符号
例子:1个byte类型数据占1 B = 8 bit,也就是1个7位二进制数字,加上一个1位表示正负号
- 1bit表示1位
- 1Byte表示一个字节
- 1B=8b
- 1024B=1KB
- 1024KB=1M
- 1024M=1G
拓展:
32位系统和64位系统的含义
1、32位和64位意思是处理器一次能处理的最大位数;
2、32位系统的最大寻址空间是2的32次方=4294967296(bit)= 4(GB)左右;
3、64位系统的最大寻址空间为2的64次方=4294967296(bit)的32次方,数值大于1亿GB。
32位系统和64位系统的区别:
1、CPU要求不同。CPU有32位和64位之分,32位的CPU只能安装32位系统,而64位的CPU既可以安装32位系统也可以安装64位系统。
2、运算速度不同。64位CPU的指令集可以运行64位数据指令,比32位CPU提高了一倍。
3、寻址能力不同。32位系统的处理器最大只支持到4G内存,而64位系统最大支持的内存高达亿位数,实际运用过程中大多数的电脑32位系统最多识别3.5GB内存,64位系统最多识别128GB内存。
4、软件兼容性不同。64位系统比32位系统的软件少,主要是64位系统推出的时间不长,所以64位系统的兼容性不如32位,虽然可以兼容32位软件,但是部分32位的软件在64位系统无法运行,但是目前的Win7 64位系统兼容性好了很多。
数据类型扩展及面试题讲解
整数拓展
| 进制 | 二进制 | 八进制 | 十进制 | 十六进制 |
|---|---|---|---|---|
| 前缀 | 0b | 0 | 无 | 0x |
注:十六进制的数字是09和AF
public class Demo1 {
public static void main(String[] args) {
int a = 0b11;
int b = 017;
int c = 19;
int d = 0x1F;
System.out.println(a);// 1*2+1
System.out.println(b);// 1*8+7
System.out.println(c);// 1*10+9
System.out.println(d);// 1*16+15
}
}
浮点数拓展
最好完全避免使用浮点数进行比较
因为浮点数能表示的字长是有限的(有些实数是无限的)且也是离散的(不是连续取值的)
浮点数存在舍入误差,只是接近但不等于
当需要比较小数的时候,一般会使用一种数学工具类BigDecimal进行比较(以后会学到),或者允许二者存在极小误差判断Math.abs(a-b) < 1E-6f
public class Demo1 {
public static void main(String[] args) {
float a = 0.1f;
double b = 1.0/10;
System.out.println(a==b);// false
System.out.println("0b"+Long.toBinaryString(Double.doubleToRawLongBits(b)));
System.out.println("0b"+Long.toBinaryString(Float.floatToRawIntBits(a)));
System.out.println(Math.abs(a-b) < 1E-6f);// true
System.out.println("====================");
float c =232323232322323f;
float d = c + 1;
System.out.println(c==d);// true
System.out.println("0b"+Long.toBinaryString(Float.floatToRawIntBits(c)));
System.out.println("0b"+Long.toBinaryString(Float.floatToRawIntBits(d)));
}
}
/*
浮点数a和b的二进制存储格式为
a:0b11111110111001100110011001100110011001100110011001100110011010
b:0b111101110011001100110011001101
十进制转二进制可能会产生无限数(即使十进制时是有限数)
因此由于4字节和8字节长度差异,a和b存在截断误差
浮点数c和d和二进制存储格式为
c:0b1010111010100110100101111111000
d:0b1010111010100110100101111111000
因为:
1 浮点数存储时,按照符号,指数,位数进行存储。
2 先将10进制数,转换成对应的二进制小数。
3 然后将小数点移至尾数第一个有效数字的右边,如果数字太大,小数点左移动得多,科学计数法指数变大,尾数变多。
4 当尾数太大,超过float或者double尾数表示范围时,将要做截断操作。
5 一个超出表示范围的大数,再加一后。此时加一很有可能被截断。
6 所有c和d没有误差
*/
详细的浮点数内存存储格式和过程:Java浮点型精度丢失问题
浮点数内存存储原理:Java 浮点数是如何存储的
此外不能使用浮点数作为循环变量
例如:精度问题会导致 (float)2000000000 == 2000000050为true,所以如下的循环不会执行:
for (float f = (float) 2000000000; f < 2000000050; f++) {
...
}
二进制和十进制互相转换
二进制数转换成十进制数
由二进制数转换成十进制数的基本做法是,把二进制数首先写成加权系数展开式,然后按十进制加法规则求和。这种做法称为"按权相加"法。
例如把二进制数 110.11 转换成十进制数。
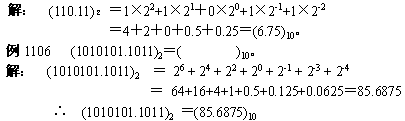
十进制数转换为二进制数
十进制数转换为二进制数时,由于整数和小数的转换方法不同,所以先将十进制数的整数部分和小数部分分别转换后,再加以合并。
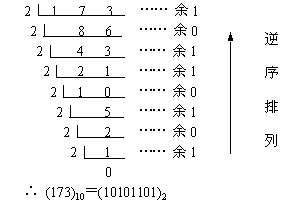
- 十进制整数转换为二进制整数
十进制整数转换为二进制整数采用"除2取余,逆序排列"法。具体做法是:用2去除十进制整数,可以得到一个商和余数;再用2去除商,又会得到一个商和余数,如此进行,直到商为零时为止,然后把先得到的余数作为二进制数的低位有效位,后得到的余数作为二进制数的高位有效位,依次排列起来。
例如把 (173)10 转换为二进制数。
解:
- 十进制小数转换为二进制小数
十进制小数转换成二进制小数采用"**乘2取整,顺序排列"**法。具体做法是:用2乘十进制小数,可以得到积,将积的整数部分取出,再用2乘余下的小数 部分,又得到一个积,再将积的整数部分取出,如此进行,直到积中的小数部分为零,或者达到所要求的精度为止。
然后把取出的整数部分按顺序排列起来,先取的整数作为二进制小数的高位有效位,后取的整数作为低位有效位。
例如把(0.8125)转换为二进制小数。
解:

字符拓展
所有字符的本质还是数字
最早的ASCII编码的范围是0~127,只包含大小写字母、数字和一些符号
中文字非常多1个字节不够,至少需要2个字节,中国因此制定了GB2312编码
可以想得到的是,全世界有上百种语言,日本把日文编到Shift_JIS里,韩国把韩文编到Euc_kr里,各国有各国的标准,就会不可避免的出现冲突,结果就是,在多语言混合的文本中,显示出来就会有乱码。
因此,Unicode应运而生。Unicode把所有的语言都统一到一套编码里,这样就不会再有乱码问题了。
Unicode标准也在不断发展,但最常用的是用2个字节表示1个字符(偏僻字符需要4个字节)。现代操作系统和大多数编程语言都直接支持Unicode。
新的问题又出现了:如果统一成Unicode编码,乱码问题从此消失了。但是,如果你写的文本基本上全是英文的话,用Unicode编码比ASCII编码需要多一倍的存储空间,在存储和传输上就十分不划算。
所以,本着节约的精神,又出现了把Unicode编码转化为“可变长编码”的UTF-8编码。UTF-8编码把一个Unicode字符根据不同的数字大小编码成1-6个字节,常用的英文字母被编码成1个字节,汉字通常是3个字节,只有很生僻的字符才会被编码成4-6个字节。如果你要传输的文本包含大量英文字符,用UTF-8编码就能节省空间。
UTF-8有个额外的好处,就是ASCII编码实际上可以被看成是UTF-8的编码的一部分,所以,大量只支持ASCII编码的历史遗留软件可以在UTF-8编码下继续工作。

ASCII、Unicode和UTF-8的关系是:Unicode是ASCII的扩展,UTF-8是Unicode的具体实现之一(unicode transformation format,还有utf-16和utf-32)
Unicode编码一般是2字节,表的数字范围是0 ~ 65535 (),一般通过转义来表示U0000 ~ UFFFF (16进制)
Unicode编码可以用双引号""也可以用单引号
public class Demo1 {
public static void main(String[] args) {
char c1 = 'a';
char c2 = 'A';
System.out.println(c1);
System.out.println((int)c1);// 强制转换数据类型为int 97
System.out.println(c2);
System.out.println((int)c2);// 强制转换数据类型为int 65
char c3 = '\u0061';// 0x0061 = 97
System.out.println(c3);
}
}
- 转义字符
首先很重要一点,转义字符是供编译器识别的。当java文件编译成.class文件后就不存在转义一说了。
比如,定义一个字符串String a值为双引号“。由于java的语法规定,字符串字面量是要由一对双引号括起来。如果这样定义String a = " " ";编译器肯定识别a为空字符串,后面不成对的双引号还会报错。这时候需要一个转义字符(java选择了\)来标识中间的双引号是字符串值,而不是语法中用来包裹字符串的特殊字符。而编译后的class文件保存值“到常量池中,不存在歧义的问题(具体可以看关于class文件讲解的文章)。
一。八进制转义序列:用于表示ascii中的字符
规则: \+1到3位8进制数字;范围'\000'~'\177'
编译器是会自动识别转义符号\后可用的数字。
比如:"\402" 超过了最大值177,编译器就会识别为改字符串为空格加上一个字符”2“,再比如”\092",9不在8进制数字中,编译器就是识别为\0和字符“92”
二。unicode转义字符:用于表示unicode字符集中的字符
规则:\u + 4个十六进制数字;范围0~65535
必须要写全4个数字,即只能写\u0000而不能写\u0
三。特殊字符:单引号'、双引号"、反斜线\
java字符串定义中,双引号必须转义,即必须这样写:"\"";而单引号可不转义,即可以这样写" ' ";
相同的字符定义中,单引号必须转义,' \' ';双引号可不转义' " ';
反斜线不管作为字符还是字符串的值都需转义
四。控制字符
\r回车
\n换行
\f走纸换页
\t横向挑格
\b退格
\r移动到本行开头
\0空字符
这里需要注意,unicode转义字符和其他转义类型,转义的位置不同,编译器在将程序解析成各种符号之前,先将Unicode转义字符转换成为它们所表示的字符。可以理解为==编译器先将源文件中unicode转义字符转成对应字符再解析代码意义==。也就是unicode转义字符只是字符的另一种写法,即\u0022(双引号)只改变u0022的字面含义,不改变它所代表的双引号的代码含义。
这就导致有些看起来语法是错的语句但实际上可以编译运行,例如
System.out.println("\u0022.length());
// 看起来显然缺少一个双引号,但是由于\u0022本身就是双引号,因此可以编译运行
反之,也会导致一些看起来没问题的语句报错,例如
System.out.println("\u0022"); 报“未结束字符串”错误
unicode转义字符有点类似于SAS的宏变量,替换过程发生在编译代码之前
拓展(以后会讲到)
public class Demo1 {
public static void main(String[] args) {
String sa = new String("hello world");
String sb = new String("hello world");
System.out.println(sa==sb);// false
String sc = "hello world";
String sd = "hello world";
System.out.println(sc==sd);// true
}
}
当"=="比较的是基本数据类型时,比较的是数值是否一致;当比较的是引用数据类型,则比较的是对象的地址是否一致。这里new String表示根据已有的字符串original来创建String对象,会创建一个新的内存地址,不管字符串是否相同,所以二者不一致。
布尔值拓展
一般只有新手才会写if (flag == true) {}这种语句,因为它完全等价于 if (flag){},此外注意与Python不一样,不可以写if (flag==1){},因为在Java中boolean true和false不对应任何数值,非要对应只能自己自定义函数
public class Demo1 {
public static void main(String[] args) {
boolean flag =true;
if (flag == true){
System.out.println("rookie");
}
if (flag){
System.out.println("veteran");
}
}
}
调试
在代码左侧行数右侧设置断点之后,点击Debug (Shift+F9) 按钮(小虫子图样)即可调试代码,会运行代码直到断点行,并显示参数和变量的变化过程,注意断点所在行是不会运行的
类型转换
由于Java是强类型语言,所以在进行一些运算的时候需要进行类型转换
运算中,不同类型的数据先转化为同一类型,然后再运算

强制类型转换
强制转换的格式:(类型)变量名
一般是从大范围到小范围进行转换(因为通常伴有截断误差)
例如
public class Demo1 {
public static void main(String[] args) {
int i = 128;
byte b = (byte)i;// 内存溢出
// 强制转换 (类型)变量名
System.out.println(i);// 128
System.out.println(b);// -128
}
}
其中由于byte类型的范围是-128 ~ 127,因此内存溢出
即128 = 127 + 1 = 0111 1111(原码)+ 0b 0000 0001(原码) = 0b 0000 0001(补码) + 0b 0111 1111(补码) = 0b 1000 0000(补码)
在计算机中所有数都是以补码形式表示和储存的,具体机制参考原码、反码、补码知识详细讲解
- 8位二进制数的取值范围为[1111 1111 , 0111 1111](原码) = [1000 0000 , 0000 0000](反码) = [-127 , 127],其中+0原码(0000 0000)和-0原码(1000 0000)的取值不一样
- 而使用补码时,0的值唯一等于0000 0000(原码&补码),原本-0的补码1 0000 0000截断后同样等于000 0000(补码),[1000 0000](补码)则用来表示-128
- -128 = (-1) + (-127) = [1000 0001]原 + [1111 1111]原 = [1111 1111]补 + [1000 0001]补 = [1000 0000]补(1 1000 0000截断后)
- 因此用补码表示的8位二进制数的取值范围是[1000 0000 , 0111 1111](补码) = [-128 , 127]
- 只有补码可以带符号位一起运算
- -128没有反码和原码表示,1000 0000(补码)计算的原码是0000 0000(原码),但其实是不对的,因为把-0和+0区分开了
因此计算机将内存溢出的128认为是127+1,计算得到的补码是1000 0000(补码),即为-128
自动类型转换
只能是从小范围到大范围进行转换
public class Demo1 {
public static void main(String[] args) {
int i = 128;
double b = i;
System.out.println(i);// 128
System.out.println(b);// 128
// 精度误差
System.out.println((int)28.7);// 28
System.out.println((int)-45.89f);// 45
}
}
注意点
- 不能对布尔值进行转换
- 不能把对象类型转换为不相干的类型
- 在把高容量转换到低容量的时候,强制转换
- 转换的时候可能存在内存溢出,或者精度问题
public class Demo1 {
public static void main(String[] args) {
char a = 'a';
int b = a + 1;
System.out.println(b);// 98
System.out.println((char)b);// b
}
}
溢出问题
操作比较大的数字时,注意溢出问题
解决方法:定义成容量更大的数据类型,并将运算表达式中任意一处数字强制转换成该类型
public class Demo1 {
public static void main(String[] args) {
// JDK7的新特性,数字中间可以用下划线分割
int money = 1_000_000_000;
int years = 20;
int total1 = money * years;// -1474836480
long total2 = money * years;// -1474836480 因为先运算再定义为long,运算结果已经是int上限了
long total3 = money * (long)years;// 20000000000
long total4 = (long)money * years;// 20000000000
System.out.println(total1);
System.out.println(total2);
System.out.println(total3);
System.out.println(total4);
}
}
变量、常量、作用域
Java是强类型语言,每个变量都必须声明其类型
Java变量是程序中最基本的存储单元,要素包括==变量名、变量类型和作用域==
变量
type varName [=value] [{,varName=[value]}];
//数据类型 变量=值 (可以用逗号隔开来声明多个同类型变量,注意跟python的格式区别)
注意:
- 每个变量都必须说明类型,可以是基本类型也可以是引用类型
- 不建议一行定义多个变量,影响程序可读性
- 可以只定义变量名和数据类型,不定义值(局部变量例外)
变量作用域
- 类变量:独立于方法之外的变量,用 static 修饰
- 实例变量:独立于方法之外的变量,不过没有 static 修饰
- 局部变量:类的方法中的变量
| 变量 | 定义位置 | 初始化值 | 生命周期 | 作用范围 | 内存位置 |
|---|---|---|---|---|---|
| 类变量 | 类中方法外以static关键字声明 | 有默认的初始化的值 | 第一次访问时创建,在程序结束时销毁 | 整个类中有效 | 静态存储区 |
| 实例变量 | 类中方法外 | 有默认的初始化的值 | 对象的存在而存在,随着对象的消失而消失 | 整个类中有效 | 堆内存 |
| 局部变量 | 方法内 | 不赋值不能用 | 方法的调用而存在,方法调用完毕而消失 | 所在方法有用 | 栈内存 |
public class Variable{
// 在类中方法之外的是属性(一种特定变量)
static int allClicks=0; // 类变量
String str="hello world"; // 实例变量
public void method(){
int i=0; // 局部变量
}
}
public class Demo08 {
// 类变量 static
static double salary = 25_000;
// 实例变量:从属于对象;如果不自行初始化,这类型的默认值为 整数(0) 浮点数(0.0) 字符(''=无) 布尔值(False)
// 除了基本类型,其余默认都是null(包括String)
String name;
int age;
// main方法
public static void main(String[] args) {
// 局部变量:必须声明和初始化值
int i =10;
System.out.println(i);
// 变量类型可以是自己定义的类
// 变量类型 变量名字 = new Demo08(); 只有变量名字可以随意命名
Demo08 demo08 = new Demo08();
System.out.println(demo08.age);
System.out.println(demo08.name);
// 类变量 static
System.out.println(salary); // 注意类变量不用new一个实例出来再调用
}
// 其他方法
public void add(){
// System.out.println(i);
// 此处报错,因为i的作用域只在定义的main方法内
}
}
还有一种静态代码块也可以定义变量,以后再说
以上在面向对象中会再详细说
常量
常量(constant):初始化(initialize)后不能再改变值,是不会变动的值
所谓常量可以理解成一种特殊的变量,它的值被设定之后,在程序运行过程中不允许被改变
关键字(修饰符):final
// final 常量名 = 值;
final double PI = 3.14;
常量名一般使用全大写字符
public class Demo09 {
// 修饰符不存在先后顺序 static和final先后顺序无所谓(包括public和private)
static final double PI = 3.14;
public static void main(String[] args) {
System.out.println(PI);
}
}
变量的命名规范
- 所有变量、方法、类名:见名知意
- 类成员变量:首字母小写和驼峰原则:monthSalary
- 局部变量:首字母小写和驼峰原则:lastName
- 常量:大写字母和下划线:MAX_VALUE
- 类名:首字母大写和驼峰原则:GoodMan
- 方法名:首字母小写和驼峰原则:runFirst()
基本运算符
Java语言支持如下运算符
- 算术运算符:+,-,*,/,%,++,--
- 赋值运算符:=
- 关系运算符:>,<,>=,<=,==,!=,instanceof
- 逻辑运算符:&&,||,!
- 位运算符:&,|,^,~,>>,<<,>>>(了解为主)
- 条件运算符:?:
- 扩展赋值运算符:+=,-=,*=,/=
扩展:在src下新建package等同于新建子文件夹用于分类整理
注意:不同package中的Java文件名和类名可以重复,但不能删除第一句声明package的语句
算术运算符
package operator;
public class Demo01 {
public static void main(String[] args){
// 二元运算符 + - * / %
int a = 10;
int b = 20;
int c = 25;
int d = 25;
System.out.println(a+b);
System.out.println(a-b);
System.out.println(a*b);
System.out.println(a/(double)b);
}
}
/*
* 30
* -10
* 200
* 0.5
* */
// 如果直接 a/b 结果会是0 因为int运算是舍去小数部分的
package operator;
public class Demo02 {
public static void main(String[] args) {
long a = 1231231232123123L;
int b = 123;
short c = 10;
byte d = 8;
System.out.println(a + b + c + d); // long
System.out.println(b + c + d); // int
System.out.println(c + d); // int
// System.out.println((String)(c + d)); // Inconvertible types; cannot cast 'int' to 'java.lang.String'
// 算数运算中只要含任何一个long类型变量 结果就是long类型
// 只要不含long类型 整数的算数运算结果一定是int类型 无论有没有int类型的运算变量
float e = 0.5F;
double f = 2.5;
float g = 1.5F;
System.out.println(e+f);
System.out.println(e+g);
// System.out.println((String)(e+g); // Inconvertible types; cannot cast 'double' to 'java.lang.String'
// 同理 算数运算中只要含任何一个double类型变量 结果就是double类型
// 但是 不同的是 如果运算只含float类型变量 结果仍然为float类型
}
}
- 整数运算
- 运算中只要含任何一个long类型变量,结果就是long类型
- 只要不含long类型,运算结果一定是int类型,无论有没有int类型的运算变量
- 浮点数运算
- 运算中只要含任何一个double类型变量,结果就是double类型
- 只要不含double类型,运算结果一定是float类型
- 整数和浮点数运算之后,结果是浮点数
关系运算符
package operator;
public class Demmo03 {
public static void main(String[] args) {
// 关系运算符返回结果是Boolean值
int a = 10;
int b = 20;
int c = 21;
System.out.println(c%a);// %称为模运算符 是一种算术运算符
// 注意跟数论里面一般的模运算不太一样 余数可以小于0 除数和被除数也都可以小于0
System.out.println(a>b);
System.out.println(a<b);
System.out.println(a==b);
System.out.println(a!=b);
}
}
/*
* false
* true
* false
* true
* */
package operator;
class Bird{//父类
}
class BigBird extends Bird{//Bird的子类
}
class LittleBird extends Bird implements BirdFly{//Bird的子类加上BirdFly接口
}
interface BirdFly{
}
public class JavaKWinstanceof {
public static void main(String[] args) {
// TODO Auto-generated method stub
JavaKWinstanceof myThis=new JavaKWinstanceof();
Bird myBird=new Bird();
BigBird myBigBird=new BigBird();
LittleBird myLittleBird=new LittleBird();
//打印各实例与类之间的关系
System.out.println(myThis instanceof JavaKWinstanceof);;//打印结果:true
System.out.println(myBird instanceof Bird);//打印结果:true
System.out.println(myBigBird instanceof Bird);//打印结果:true 子类实例出的对象也是父类的实例
System.out.println(myBird instanceof BigBird);//打印结果:false 父类实例出的对象不是子类的实例
System.out.println(myLittleBird instanceof Bird);//打印结果:true 子类加上其它接口后实例出的对象也是父类的实例
}
}
自增自减运算符、初识Math类
package operator;
public class Demo04 {
public static void main(String[] args) {
// 一元运算符 ++ -- 自增 自减
int a = 3;
int b = a++; // 先执行完等号右边的代码,给b赋值,再自增
// 等价于int b = a; a = a + 1;
System.out.println(a);
// 等价于a = a + 1; int c = a;
int c = ++a; // 先自增,执行完等号右边的代码,再给b赋值
System.out.println(a);
System.out.println(b);
System.out.println(c);
// 很多运算会使用一些工具类操作 例如数学运算会经常使用Math类
// 幂运算 2^3 = 2**3 = 2*2*2 = 8
double pow = Math.pow(2, 3);
System.out.println(pow);
}
}
/*
* 4
* 5
* 3
* 5
* 8.0
* */
逻辑运算符、位运算符
注意:
- 逻辑与运算如果第一个变量是false,则结果一定是false,因此不会运行第二个变量
- 逻辑或运算如果第一个变量是true,则结果一定是true,因此不会运行第二个变量
称为短路运算
package operator;
// 逻辑运算符
public class Demo05 {
public static void main(String[] args) {
// 与 (and) 或 (or) 非 (取反)
boolean a = true;
boolean b = false;
System.out.println("a && b : " + (a && b)); // 逻辑与运算:两个变量都为真结果才为true
System.out.println("a || b : " + (a || b)); // 逻辑或运算:两个变量有一个为真,则结果才会true
System.out.println("!(a && b) : " + !(a && b)); // 逻辑非运算:假if真,真if假
// 短路运算
int c = 5;
boolean d = (c < 4) && (c++ < 4);
System.out.println(d); // 与运算的第一个变量已经是false了,结果一定是false
System.out.println(c); // c仍然为5说明根本没执行 && 后面的内容
boolean e = (c > 4) || (c++ < 4);
System.out.println(e); // 或运算的第一个变量已经是true了,结果一定是true
System.out.println(c); // c仍然为5说明根本没执行 || 后面的内容
}
}
/*
* a && b : false
* a || b : true
* !(a && b) : true
* false
* 5
* true
* 5
* */
(面试常考)
提问:2 * 8 = 16怎么运算最快
答:用2<<3代替2*8,因为位运算最快,效率最高
注意:以下位运算实际都是对补码做的,只是除了位取反之外,其他位运算对原码和补码计算结果都一样
package operator;
// 位运算符:跟二进制有关
public class Demo06 {
public static void main(String[] args) {
// 按位与& 按位或| 按位非~ 按位异或^ 按位取反~(连带符号位一起取反)
/*
* A = 0011 1100
* B = 0000 1101
*
* A&B = 0000 1100
* A|B = 0011 1101
* A^B = 0011 0001 (异或是二者不一样为1,一样为0)
* ~B = 1111 0010
* */
int A = 0b00111100;
int B = 0b00001101;
String str1 = Integer.toBinaryString(A & B);
String str2 = Integer.toBinaryString(A | B);
String str3 = Integer.toBinaryString(A ^ B);
String str4 = Integer.toBinaryString(~B);
int i1 = Integer.parseInt(str1);
int i2 = Integer.parseInt(str2);
int i3 = Integer.parseInt(str3);
// 这里因为 ~B 是负数-14,int类型占内存空间32位按补码形式存储(负数的补码前面有很多1),若按字符转为int会超出int的上限,所以直接截取后8位即可
String r1 = String.format("%08d", i1);
String r2 = String.format("%08d", i2);
String r3 = String.format("%08d", i3);
String r4 = str4.substring(str4.length()-8, str4.length());
System.out.println("A & B : "+(A&B)+" = "+r1);
System.out.println("A | B : "+(A|B)+" = "+r2);
System.out.println("A ^ B : "+(A^B)+" = "+r3);
System.out.println("~B : "+(~B)+" = "+r4);
// A & B : 12 = 00001100
// A | B : 61 = 00111101
// A ^ B : 49 = 00110001
// ~B : -14 = 11110010
// 提问:2 * 8 = 16怎么运算最快 答:用2<<3代替2*8,因为位运算最快,效率最高
// 左移<< 有符号右移>> 无符号右移>>>
/*
* 0000 0000 0
* 0000 0001 1
* 0000 0010 2
* 0000 0011 3
* 0000 0100 4
* 0000 1000 8
* 0001 0000 16
* a<<b就是把a的二进制数字往左移动b位,等同于a * Math.pow(2,b),右侧补000…
* a>>b就是把a的二进制数字往右移动b位,等同于a / Math.pow(2,b),右侧舍去,左侧用符号位补所有空缺的位置
* >>>是无符号右移 >>是有符号右移 没有无符号左移
* 有符号右移>>就是右移之后,左边的补上符号位,正数补000…,负数补111…
* 无符号右移>>>就是右移之后,无论该数为正还是为负,右移之后左边都是补上000…
* 左移<<不区分有符号和无符号,都是左移之后右边补上0,最左边的符号位也直接移走,所以大数字左移有可能会导致符号变化
* a>>>b无法写成等价的数学运算形式,但是对于a>0来说,与a>>b是一样的
* */
System.out.println("java 右移");
int a = -5;
System.out.println(Integer.toBinaryString(a));
System.out.println(Integer.toBinaryString(a >> 2)); // 有符号右移
System.out.println(Integer.toBinaryString(a >>> 2)); // 无符号右移
// java 右移
// 11111111111111111111111111111011
// 11111111111111111111111111111110
// 111111111111111111111111111110 注:前边的两个0被省略了
System.out.println("java 负数 左移");
int b = Integer.MIN_VALUE;
System.out.println(Integer.toBinaryString(b));
System.out.println(Integer.toBinaryString(b << 2));
// java 负数 左移
// 10000000000000000000000000000000 // 前面说过,用1000……0000来表示最小值的目的是为了区分+0和-0
// 0 注:不保留符号位,符号位直接移走
System.out.println("java 正数 左移");
int c = 5;
System.out.println(Integer.toBinaryString(c));
System.out.println(Integer.toBinaryString(c << 2));
// java 正数 左移
// 101
// 10100
}
}
手动计算位取反结果方法:
先将数字化为二进制补全应有的字节(int是32位),根据数字的原码计算补码,然后将补码各位置取反,再根据取反后的补码计算原码,将原码化作十进制即可
例如:上例中B=13,即0000 1101,补码等于本身,~0000 1101 = 1111 0010,1111 0010(补码)=1111 0001(反码)=1000 1110(原码)= -14,即~B = -14,计算过程实际是32位但是这楼里省略了中间的0000……和1111……结果是一样的
三元运算符及小结
以下运算符都是用来偷懒的
扩展赋值运算符及字符串连接符
package operator;
public class Demo07 {
public static void main(String[] args) {
int a =10;
int b =20;
a+=b; // a = a+b
System.out.println(a);
// 30
a-=b; // a = a-b
System.out.println(a);
// 10
// 字符串连接符 + 只要两侧有一个变量是String类型,就会把另一侧的变量也自动转换为String,再进行连接
System.out.println(a+b);
// 30
System.out.println(""+a+b);// 这里""先和a进行连接,变成"10",再和20进行连接
// 1020
System.out.println(a+b+"");// 这里a+b先进行计算,得到30,再和""进行字符连接
// 30
}
}
三元运算符(条件运算符)
package operator;
public class Demo08 {
public static void main(String[] args) {
// x ? y : z
// 如果x==true,则结果为y,否则结果为z
int score = 80;
String type = score < 60 ? "不及格" : "及格";
// 等同于if语句
System.out.println(type);
// 及格
}
}
运算符优先级
运算符大致优先级:括号,一元运算符,一般二元运算符,三元运算符,赋值运算符与扩展赋值运算符
结合性:同等优先级情况下,在代码中的计算顺序(一般是从左向右计算,但有例外)
详细如下:(优先级2中的+和-不是算数运算符而是一元运算符,表示正负号)
| 优先级 | 运算符 | 结合性 |
|---|---|---|
| 1 | ()、[]、{} | 从左向右 |
| 2 | !、+、-、~、++、-- | 从右向左 |
| 3 | *、/、% | 从左向右 |
| 4 | +、- | 从左向右 |
| 5 | «、»、>>> | 从左向右 |
| 6 | <、<=、>、>=、instanceof | 从左向右 |
| 7 | ==、!= | 从左向右 |
| 8 | & | 从左向右 |
| 9 | ^ | 从左向右 |
| 10 | | | 从左向右 |
| 11 | && | 从左向右 |
| 12 | || | 从左向右 |
| 13 | ?: | 从右向左 |
| 14 | =、+=、-=、*=、/=、&=、|=、^=、~=、«=、»=、>>>= | 从右向左 |
注意:多数运算符具有左结合性,一元运算符、三元运算符、赋值运算符具有右结合性
package operator;
public class RightAssociation {
public static void main(String[] args) {
// 结合性问题
// 三目运算 ?:
int a = 3;
int b = 2;
int c = 1;
int result = a > b ? a : b > c ? b : c;
//如果是左结合:
// a > b ? a : b 先计算,得到结果是a
// a > c ? b : c 后计算,得到结果是b
// result = b = 2
// 如果是右结合:
// b > c ? b : c 先计算,得到结果是b
// a > b ? a : b 后计算,得到结果是a
// result = a =3
System.out.println("result=" + result);//结果是3,证明三目运算符是右结合的,即从右向左运算
//单目运算符 ++ -- ~ ! (type) sizeof
int single = 2;
int re = ~ single ++;
//左结合的话:
// ~ single 先计算,得到结果是-3;single=2 (计算取反结果:~00…0010 -> 11…1101 -> 11…1100 -> 10…0011 = 等于-3)
// re = -3++后计算,得到结果是re=-3;single=3;
//右结合的话:
//temp=single;single=single+1; 其结果temp=2;single=3
//re = ~ temp;~00000010(正数补码等于原码)得到11111101(补码),11111100(反码),10000011(原码),即 re = -3
System.out.println("re=" + re);//re =-3
System.out.println("single=" + single);//single=-3
/*
* 计算错了
* 以上举例不能体现单目运算符的右结合性,但是对于理解"后加加"赋值的过程很有帮助
* */
}
}
包机制
为了更好地组织类,Java提供了包机制,用于区别类名的命名空间
包(package)的本质就是文件夹
包语句的语法格式为:
package pkg1[.pkg2[.pkg3…]];
// 其中.是区分包的上下级路径分隔符
规范:一般利用公司域名倒置座位包名
例如www.baidu.com是公司域名,那包名就为com.baidu.www
如果无法创建多级空包,则在 project面板 > show options menu齿轮 > compact middle packages 取消勾选
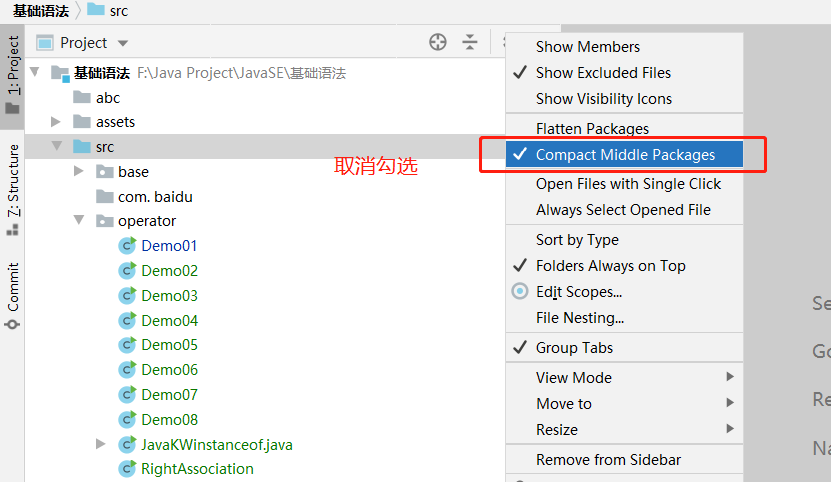
正确建立com.baidu.www的包,应该如下
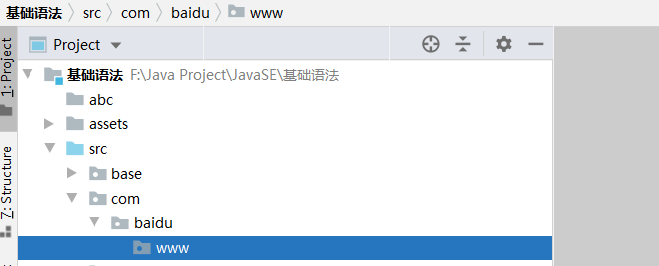
同理可以建立com.baidu.wenku或者com.baidu.zhidao等等其他包,等效于在baidu下面新建子包
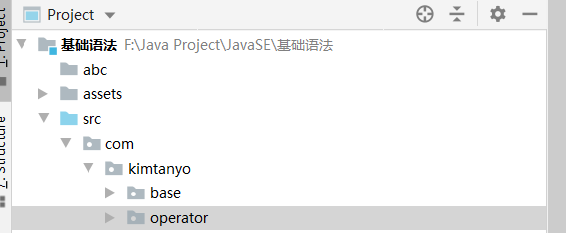
然后按照规范重新格式化之前的包名如下
其中的java类在idea中经过refractor,会在最上方自动补充一句package com.kimtanyo.operator;(但是要刷题要记得手动加)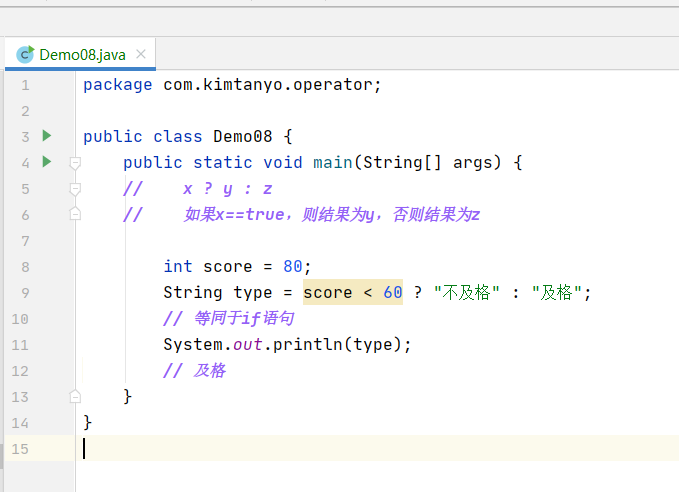
为了能够使用某一个包的成员,我们需要在Java程序中明确导入该包,使用import语句可以完成此功能
import package1[.package2…].(classname|*)
例如:
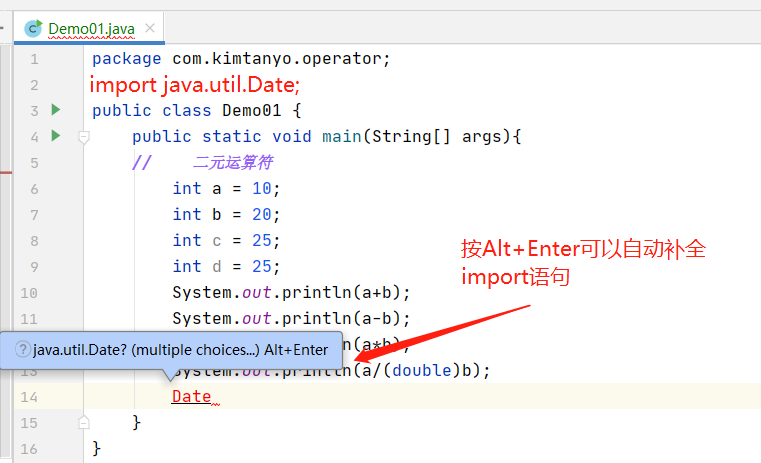
也可以导入自定义包中的java文件,但是注意导入的java文件所定义的类名不可以和当前java文件的类名重复
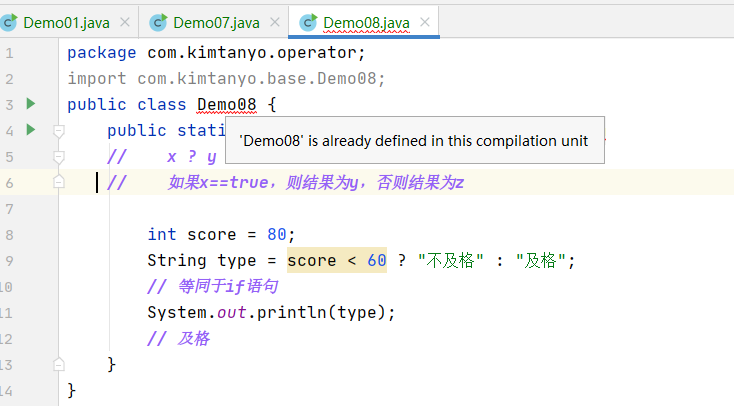
另外如果想导入某个包下所有的成员,可以使用通配符*
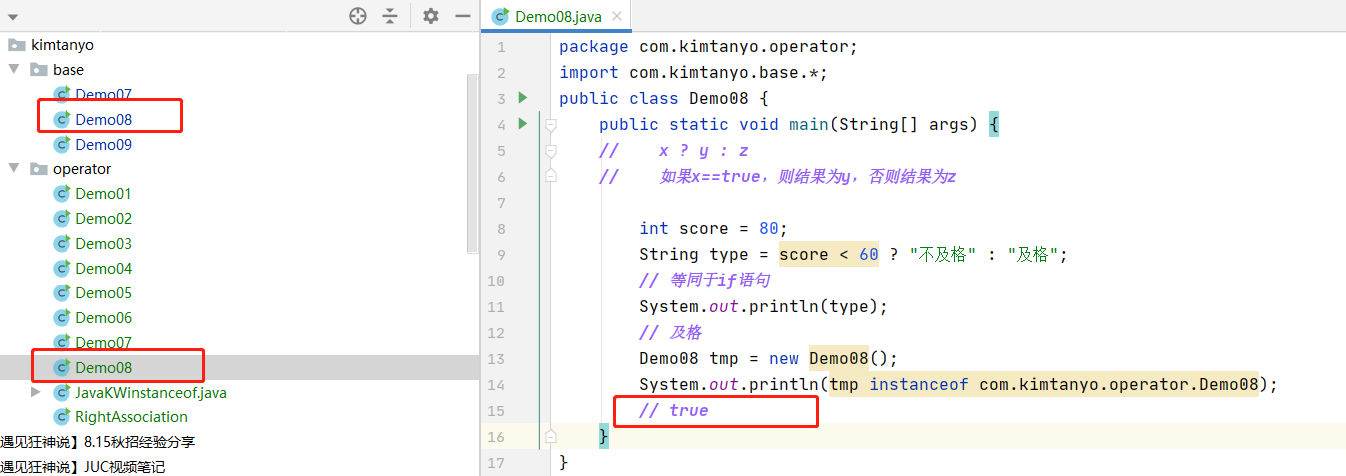
注意:如果导入的包中有类名和当前java文件类名重复,此时不会报错,但是在引用的使用会优先使用当前java文件的类
课后:看阿里巴巴Java开发手册
JavaDoc生成文档
JavaDoc命令是用来生成自己API文档的
参数信息
- @author 作者名
- @version 版本号
- @since 指明最早需要使用的jdk版本
- @param 参数名
- @return 返回值情况
- @throws 异常抛出情况
文档注释
文档注释分为类注释和方法注释,注意类注释写在类定义前面,方法注释写在方法定义前面,中间不要隔其他内容
快捷键是输入/**,然后回车,尤其是方法注释会自动补全内容
package com.kimtanyo.base;
/**
* @author kimtanyo
* @version 1.0
* @since 1.8
*/
public class Doc {
String name;
/**
*
* @param name
* @return
* @throws Exception
*/
public String test(String name)throws Exception{
return name;
}
}
javadoc命令行
打开java文件所在文件夹
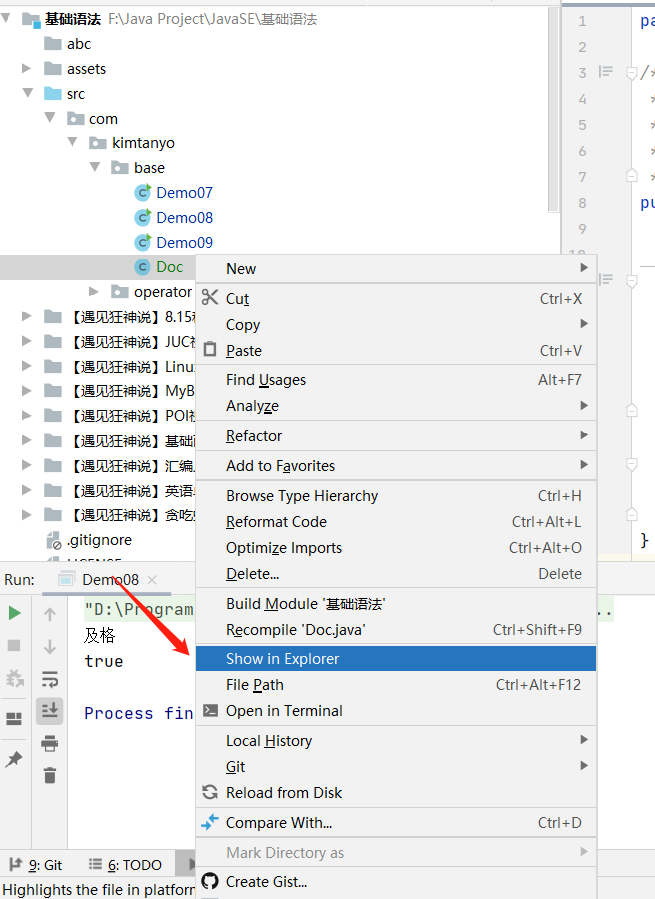
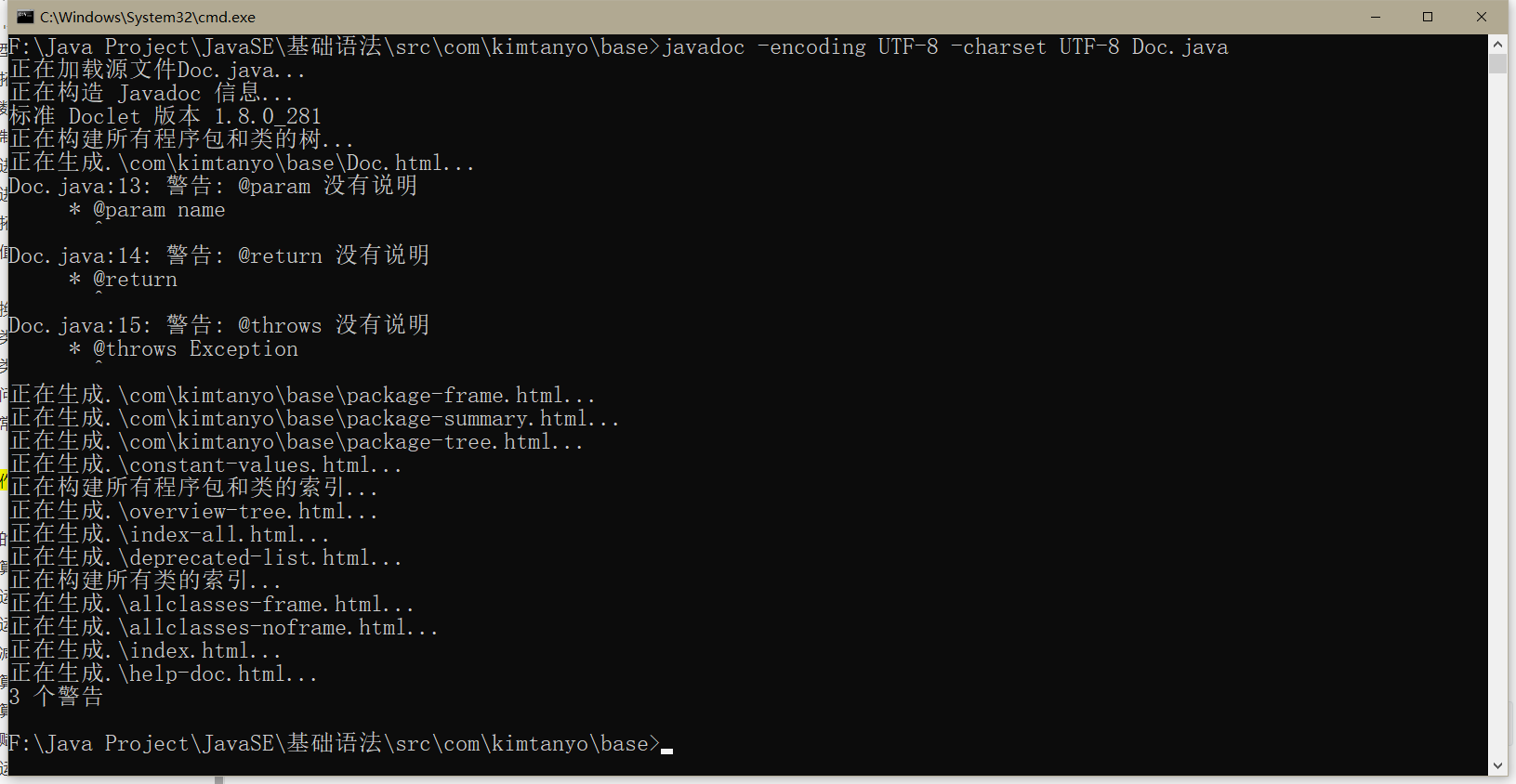
在文件夹导航栏输入cmd,在当前java文件的路径打开命令行,输入javadoc命令,生成指定java文件的文档,但是如果java文件中有中文,防止出现乱码,因此要用UTF-8编码且让字符集也为UTF-8
# 格式:javadoc 参数 java文件名
javadoc -encoding UTF-8 -charset UTF-8 Doc.java
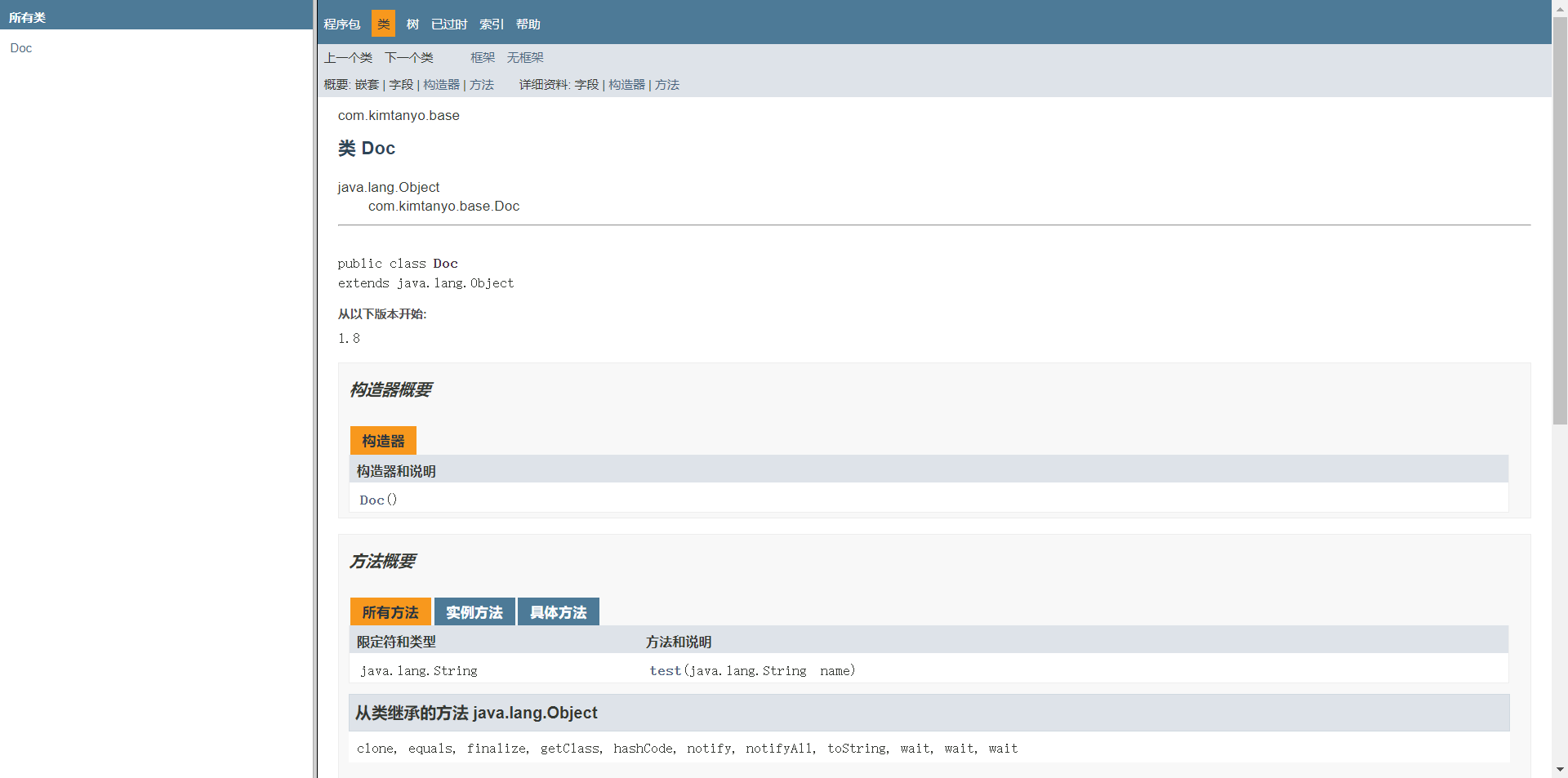
生成成功以后打开目录索引页index.html,会得到一个跟官方API文档极其类似的文档,打开index中的Doc类,会得到一些说明
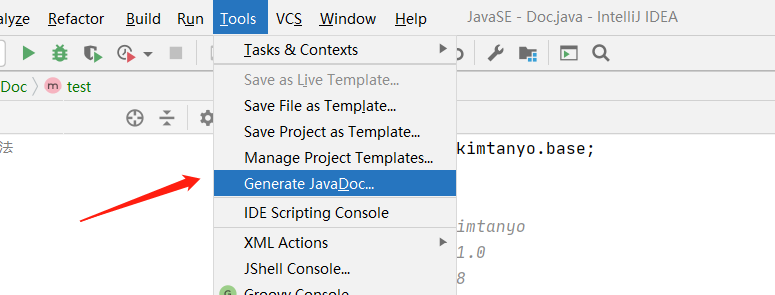
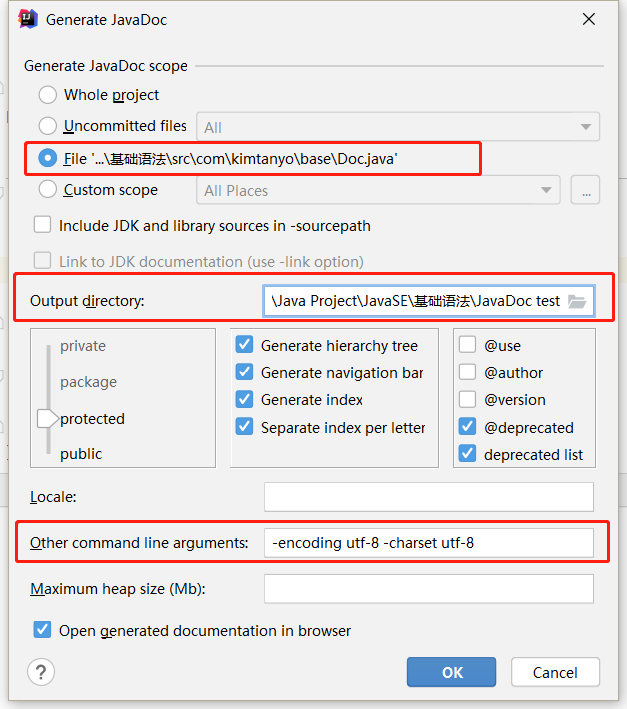
IDEA生成JavaDoc文档
打开Tools -> Generate JavaDoc,选中java文件、输出路径和参数即可生成